

News
International Journalism Festival 2026: the events you shouldn’t miss in Perugia

Screenshot of the VerificAudio website. | Credit: PRISA Media
Olalla Novoa is a journalist and product manager at PRISA Media, a transnational media group based in Spain. She is responsible for the Voice and Smart Speakers area at PRISA Media, where she also works on AI related projects. In this piece she explains how she and her colleagues created VerificAudio, an experimental tool to detect audio deepfakes.
VerificAudio is a tool for journalists to verify audio and detect any deepfakes created with synthetic voices in Spanish. Our goal is not only to provide support to reporters and editors in our radio stations, but also to reinforce listeners’ trust in the face of misinformation.
At PRISA Media we believe this will be one of the key challenges audiences will face with the rise of generative AI. We are the largest audio producer in Spanish worldwide, with more than 30 leading radio brands in Spain, Colombia, Chile and Mexico, and we have created a deep relationship of trust with our listeners for many decades. In this new ecosystem where voice cloning can be weaponised, we believe it is our responsibility to strengthen this relationship with the development of a tool that helps our journalists verify any suspicious audios.
We started working with synthetic voices in 2022. Our first experiment was Victoria, the voice of football, a virtual assistant for smart speakers. Since then, we have seen voice cloning technologies improving their quality and processing speed. They have also emerged as open source software and even as online services. This makes it easy and cheap to generate a credible replica of anyone’s voice in a matter of minutes.
This is why fake audios have sneaked into social media platforms and into messaging apps such as Telegram or WhatsApp, used by millions of Spanish-speakers around the world. What started as satire using celebrities’ voices for jokes or comedy purposes has quickly evolved into a real threat to trust in news and the public sphere more broadly.
A couple of recent examples were the infamous fake Joe Biden’s robocalls and fake audios that appeared to show London mayor Sadiq Khan making inflammatory remarks before Armistice Day.
We could also face the opposite problem: powerful people falsely claiming they’ve cloned their voices after being caught in embarrassing situations.
These are the problems we wanted to tackle and we wanted to tackle them fast as the world entered this year of elections, with AI-generated audio threatening to become a potential source of misinformation in countries like Mexico and Spain.
With all these problems in mind, we started working on an audio fact-checking platform that would support journalists on their quest to verify any dubious audios.
The project was powered by the Google News Initiative as part of a push to fight misinformation, share resources and build a diverse and innovative news ecosystem. Initially conceived as a Caracol Radio project (PRISA Media’s radio unit in Colombia), VerificAudio has been developed by Minsait, a Spanish tech company with operations in more than 100 countries. Plaiground, Minsait’s AI business unit, used natural language processing (NLP) and deep learning to evaluate any audio manipulation.
Before machine learning algorithms can extract any meaningful information from the audio, it is essential to prepare and normalise audio files, improve data quality and reduce unwanted variability that could interfere with the model training process. Our tool does this work through a process that includes noise reduction, format reconversion, volume equalisation, and temporal cropping.
Once our dataset was ready and after an exhaustive algorithmic evaluation and selection process, we settled for two complementary approaches: neural networks and a machine learning-based model.
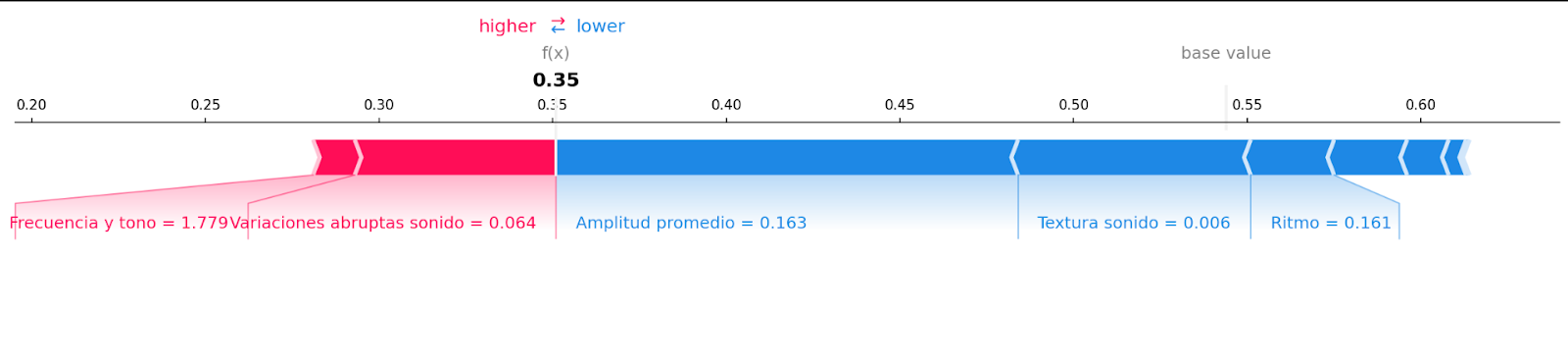
For our machine learning model, Plaiground’s team analysed which audio features (the physical properties that are extracted from an audio signal) had a greater impact on the prediction made by the AI model. Plaiground’s engineers also defined a set of KPIs that would later allow them to validate results and confirm that the model was right in detecting deepfakes while minimising the number of false positives. In this individual identification mode, an explainability graph (see screenshot below) shows the importance and weight of each of the audio features, allowing users to understand which aspects of the audio most influence our model’s prediction.
At the same, we pursued the neural networks approach, fine-tuning an existing open-source model and adapting it to the Spanish language. This approach compares two audios and determines if they are from the same person, from two different people, or if they’ve been generated by a synthetic process. The model converts each audio into a feature vector that represents the unique peculiarities of the voice, capturing aspects such as pitch, intonation, and speech patterns. Then it compares each pair of vectors.
We decided to keep both models (machine learning and neural networks) as part of our toolbox, implementing a double-check protocol to increase accuracy and minimise the number of false results. In parallel, we developed an online interface to simplify any trials by non-technical people.
We believe audio deepfakes are going to gain traction in the following months, but at this point it is hard to compile a big corpus of fake audios in Spanish. We tried to find examples on social media. But at the end of the day, we ended up generating our own dataset by using different cloning technologies available in the market and mimicking real fake audios we had come across in our search.
Our colleagues at Caracol Radio in Colombia played an essential role in this process, providing audios from our own archives and new audios generated by people in the team. Since our models focus on audio features and patterns, and not on the length of each audio file, we could split some of the longer files to multiply our dataset with training purposes.
This is an ongoing project and will require constantly refining our models and considering new cloning technologies and new ways of producing fake audios that will eventually surface.
When working with AI, two common hurdles are traceability and explainability. Big neural models work like a black box: they offer you results, but they don’t give you any elements to interpret how they reached those results. That’s why we think it is important to have a two-prong process, with our machine learning model pointing out which audio attributes had a major role in a decision.
Validating the results means seeing how reliable they are if you compare them with human judgement. In order to test our models, we compiled a new dataset of real and fake audios to test both models both mechanically and manually. This dual approach, combining the power of artificial intelligence with human expertise, helped us ensure a more accurate and comprehensive assessment of the platform's ability to detect audio manipulations.
This process not only helped us identify inaccurate results. It also allowed us to retrain and refine our models, and gave us key information to improve our user interface and make it more accessible. The process also made us aware of the difficulty of ranking results and the need to consider a probability approach that helps the journalist make a decision. When detecting deepfakes, it is not feasible to offer absolute results, but rather a tendency towards real or false. In VerificAudio, this translates into a percentage that guides journalists, who have to make a final decision within their own fact-checking processes.

Our VerificAudio interface is now accessible for all verification teams in PRISA Media’s radio stations in Spain, Colombia, Mexico and Chile. We believe AI is just a tool and in no way replaces current fact-checking protocols.
When our journalists come across a suspicious audio file, they send it to the verification team, which then works with the beat reporter to evaluate the file, its origin, the distribution channels in which it’s been shared, its news context and any similar audios available, as well as the AI analysis done with VerificAudio. We are also creating a double repository: one with verified audio files for well-known figures that speeds up the comparison process, and another one with fake audio files that we’ll use to keep training our models.
VerificAudio’s interface is simple and easy to use. It allows users to upload a suspicious audio file and a real audio file from the same person, and check for the results of the analysis. Users can choose between two different verification options: comparative mode and identification mode.
In comparative mode, VerificAudio will show them if the files belong to the same speaker, to different speakers or to a cloned voice. In identification mode, the tool will indicate if the audio file ingested is likely to be real or synthetic offering a coefficient and a list of the main attributes taken into account in the result.
VerificAudio has been conceived as a tool in constant evolution and will need to be updated as new technologies emerge. Our goal is to keep expanding the diversity of the dataset for model retraining, refining its results and including increasingly larger samples of deepfakes.
We’ll keep improving our sample by taking into account different Spanish accents from around the world. In the future we would like to be able to expand the scope of the tool to other languages in Spain such as Catalan, Euskara or Gallego.
In parallel, we are improving our tool to scale up access and developing an online platform where we can publish the analysis done by our newsrooms. This site will include educational resources so that our audiences can learn about deepfakes.
For now, VerificAudio is just an internal resource to be used within PRISA Media newsrooms. Our verification teams will also analyse audios anyone sends through the site of the project.
We believe the web platform we are developing will also play an important role in providing an overview of the deepfake audio verification landscape, and we do not rule out opening access to other media companies in the future once the tool has been improved and scaled up.
In every email we send you'll find original reporting, evidence-based insights, online seminars and readings curated from 100s of sources - all in 5 minutes.
In every email we send you'll find original reporting, evidence-based insights, online seminars and readings curated from 100s of sources - all in 5 minutes.

