
Podcasts
Our podcast: Digital News Report 2026. Episode 4: How people are using AI chatbots for news


Hanna Barakat + AIxDESIGN & Archival Images of AI / Better Images of AI / Frontier Models 3 / CC-BY 4.0
A Nordic media company began a collaboration with university researchers to develop AI systems for news media independently of large technology companies in October 2020, in the midst of the COVID-19 pandemic and a little over two years before the launch of ChatGPT.
The company was Danish publisher JP/ Politikens Media Group and the initiative was the Platform Intelligence in News (PIN) project. It spanned three years and nine months and resulted in several AI applications now used by the company’s titles.
Nordic newsrooms have been amongst the early adopters of AI, testing and incorporating new tools into their workflows ahead of their colleagues elsewhere. Denmark’s JP/ Politikens Media Group publishes several titles, including tabloid Ekstra Bladet and broadsheet Jyllands-Posten, and reaches three million Danes every month.
The PIN team was around 17 people, comprising researchers from the Copenhagen Business School, the University of Copenhagen and the Technical University of Denmark as well as JP/Politikens’ journalists and media workers. The project, which comprised research, development and roll-out of newsroom AI tools, was partly funded by state-owned investor Innovation Fund Denmark, which focuses on innovative projects with potential to benefit Danish society.
After PIN came to an end in June 2024, the team behind the project authored a report with insights from their work. The report was published in November and detailed key takeaways that could be useful to other newsrooms around the world.

Some fruits of the project include the multitasking tool Magna, an API chatbot designed to assist journalists with a variety of tasks including transcription and text analysis, and a recommender system to create a personalised feed for audiences. The report includes recommendations to adapt AI tools to news and editorial values, work alongside technology experts and colleagues from the news industry, and be ready to monitor and change your workflows as the technology changes.
The report also introduces the idea of a ‘values compass’: a visualisation of both the initial steps in the process of developing AI tools for the newsroom and a breakdown of the values to be considered. These are split into reader, journalistic, business and technical values. Technical values include the accuracy and the robustness of the systems being built; reader values are concerned with news experience and reader autonomy; business values cover the impact of the new tech on revenue; and journalistic values are those followed by any newsroom.
In terms of the process, it begins with a definition of the general purpose of the news publisher, followed by connecting that purpose with the values, and finally using both to guide the start of the development of new tools.
I spoke to Kasper Lindskow, lead author of the report and Head of AI at JP/Politikens Media Group. Lindskow was the PIN project’s manager and the best person to dive deeper into some of the themes of the report, including how the team developed the recommender system and how they have been experimenting with generative AI.

Q. Were there any ideas you decided not to pursue as they were conflicting with the values in your compass?
A. There wasn't any technology that we considered not using at all. But these values had a big impact on how we use technologies. For recommender systems, for example, we made a ban on using sentiment signals as an input. In the project, we developed sentiment analysis models that analyse the emotions news articles bring out in the audience. But we decided that it would be wrong to allow a system to optimise directly on those values.
We allowed recommender systems to optimise to predict reader interests, but we constrained them to make sure that they didn't stray too far from journalistic values. For example, we have a list of types of articles they can't recommend at all, such as violent crime. We have some types of topics for which we limit the amount of articles we serve.
Q. Can you tell us more about what you did with recommender systems?
A. Our basic idea here was that recommenders could be used to create value for publishers both journalistically and also business-wise. We also had a pretty clear idea that there are many different types of recommender systems and many ways of building them: each works well in a different context.
Recommender systems are working well on Netflix or YouTube. But what we quickly found out was that the types of recommender systems that they use don't work well in a news publishing context. So we had to develop new methods that were designed specifically for news and aligned with all our value bubbles.
You usually distinguish between collaborative filtering systems and content-based systems. Collaborative filtering systems were invented by Netflix 20 years ago or so. The way they work is by looking at differences and similarities between many different users. If two are similar, but one hasn't yet seen a show the other has seen, it’ll recommend that to them. But this doesn't work very well for news: because the pace is too fast, those types of models can't learn fast enough. Content-based systems, on the other hand, can do that.
One important learning here is that you need to adapt your methods to the domain you're working on. The other important learning is that you also need to align them with your values. If you let them completely optimise only towards reader interests, they will gravitate too much towards that and you might lose some of the initial concerns you want to consider. You need to find some ways of balancing these two goals.
Q. How do you do that?
A. As news publishers who've been around for 150 years or longer, we have always worked on balancing reader interests with our values. In the print era, we did that by having two editions of the newspaper per day where we published a mix of news stories that balanced that value set. In the early days of digital journalism, we did it in a single news flow for everyone that was updated continuously throughout the day. And we need to do the same now that we're using personalized news flows.
If you do this right, recommenders can definitely predict real interests. But we want to make sure that they don't stray too much from what a human would usually recommend.
Q. Did you establish a feedback loop with your audience to have their input on this?
A. Only indirectly. The main balance here has been between the newsroom and the developers. We had some user studies, including both studies of audience behaviour and qualitative studies such as user workshops and focus groups. We also tried to get the readers directly engaged by telling them whenever they were touched by an algorithm and making it clear that they could contact us to give us feedback. But they didn't do it.
We tried to be very transparent about all recommender systems and all types of algorithms as well because we thought the readers would care. They do care when you ask them, but you can't really see it in their behaviour.

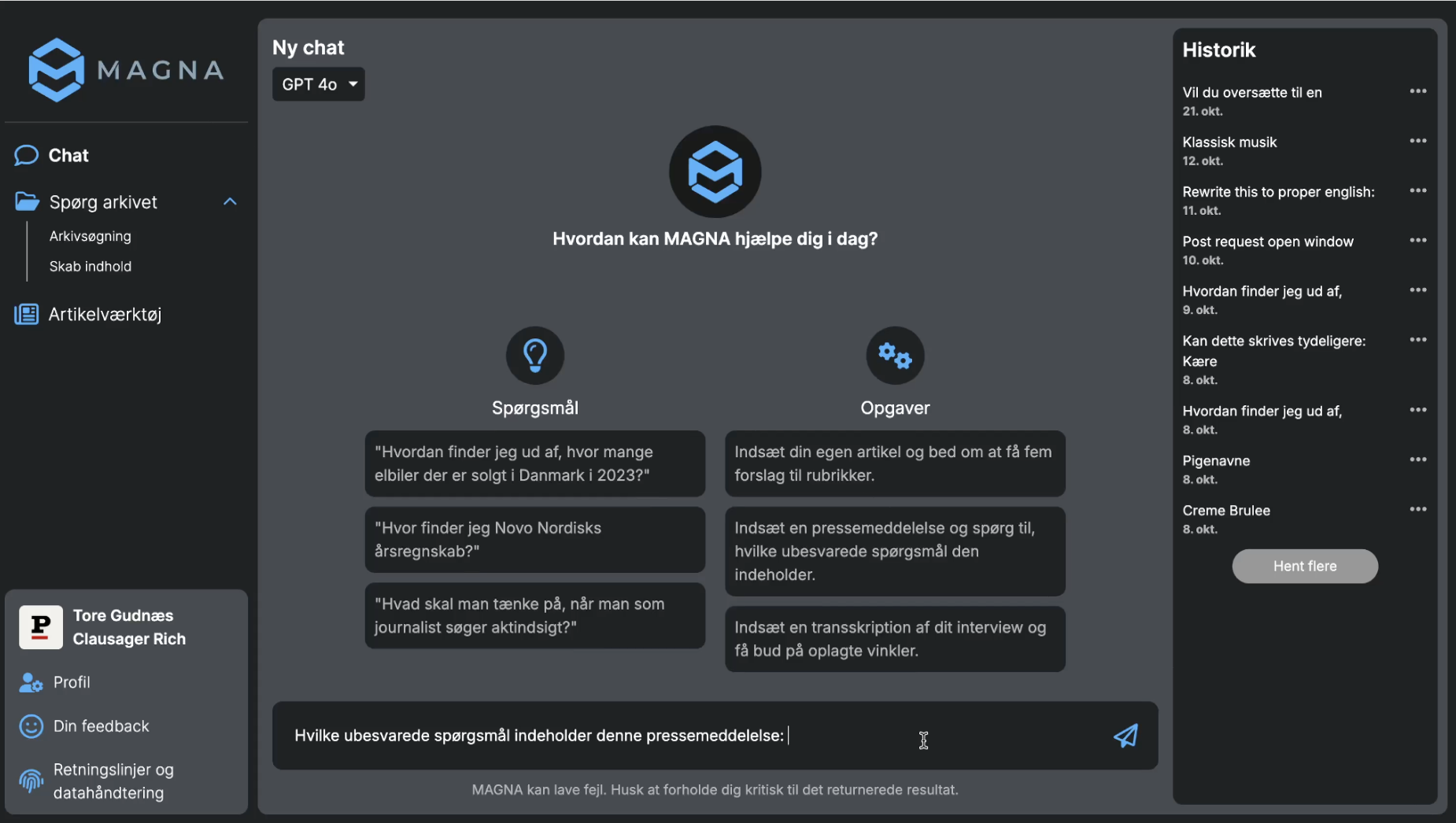
Q. With regards to Magna, I saw in the report that you've been testing the tool to produce article drafts. How did these tests go? And what role do you envision this to take in the newsroom?
A. We rolled out an early version of Magna at [our tabloid] Ekstra Bladet a year ago. Now we're rolling out a more mature version to all news brands, which is focused on writing assistance and story enrichment. We expect that this will be used to enable routine tasks to be performed more efficiently.
A core challenge here isn't so much factuality or hallucination issues if you use the models in a specific way and ground and prompt them strictly. The main challenge is getting the tone right and the perspective, the angles that a news brand will typically put on the stories. But we do think that we've gotten quite far in making sure that it isn't just generic median content, that it does align with our voice.
The output isn't directly publishable. It shouldn't be, that's not the ambition. Even though we've gotten pretty far in aligning with each tone of voice, this area is still where we have the most work to do going forward.
Q. Which topics would you use this for? Which type of article?
A. It's going to be interesting to see in the sense that it's all up to the journalists. It can be used to draft many different types of stories, this technology is flexible. A lot of the tools that are included in this version of Magna are really basic. So correction, adaptation to the writing guidelines of the individual publication, shortening the article. Those functions will be used the most, and they just save a journalist 10 minutes of proofreading their own story.
Journalists are experimenting a lot with article drafting, but also all sorts of other tasks, like creating the weekly travel quiz. The intention now is that journalists continue working on the draft and then publish it as they usually do. Getting the most value out of it will also require front-end work, making sure that the systems on the website can support new quiz formats, for example. It always takes longer than you think because you need all this supporting work done before you can use it efficiently.
Q. Aside from quizzes, what other examples of ‘story enrichment’ can you give?
A. At this point, it's small use cases, such as creating a fact box and writing a story summary across multiple articles. For the next generation of Magna, we’re working on enriching the story once it’s ready by creating different types of text versions for different audiences, and different channels. For example, audio versions. We want to enable a journalist to say, this story or this theme deserves a user-facing chatbot so that a user can dialogue with it. This is the next generation of Magna that isn't out yet. Right now, we are in the prototyping stage.
Q. Have you experienced an impact on revenue since the beginning of the project?
A. We have seen the biggest impact coming from our recommender systems, both as drivers of traffic and as a driver of subscriptions. Recommender systems provide the best business case you can find right now for AI.
We haven't found strong effects for generative AI, but also because we haven't looked for them yet. It's too early for that. The technology just came out two years ago. Right now, it's being turned into tools. Once those tools are rolled out, then we’ll be able to measure the effects.
We also talk a lot about the use of AI to produce metadata, which there is less public awareness about. That's valuable for so many different cases, but it can be hard to track the business value of something like that. The impact can come from the ‘read more’ lists in terms of more engagement and more traffic, but often it just goes into bigger systems where the effect becomes harder to track.
Q. What are the advantages for newsrooms of taking the time and resources to build their own AI tools instead of just taking off-the-shelf solutions?
A. In some cases it might be fine to use off-the-shelf AI tools. But there are three reasons why it can be better to make them yourself. One is technical: sometimes you need to integrate the tool into your own systems, which is hard to do for a vendor. The next one is about internal alignment, and that's the most important reason. For example, if a publisher goes to an external vendor to buy recommender systems, the systems they offer might be revenue-optimised, but the news domain is different.
The third reason concerns our dependence on tech giants. I don't think this is a big issue with recommender systems, but it is with language technology at this point. As publishers, in earlier waves of digitisation, we became too dependent on tech giants and that hurt us a lot. In the big wave of social media, publishers were too fast in putting all that content out there and installing all those buttons on their websites, enabling tech giants to harvest all their data and use it to compete with them in the advertising market, which has caused part of the structural decline we've seen in publishing revenue.
On the other hand, there can also be reasons sometimes not to do it yourself because it is demanding. Some of the generative AI models take massive resources and you can’t build them yourself.
Q. What are some first steps that regular newsrooms with a limited budget can make towards working with AI?
A. It's not easy to get an interdisciplinary project like PIN going, but I certainly recommend news publishers to do more of that. Getting started with generative AI is very easy at this point. You can buy access to a tool and start experimenting with it. If you do that, remember to have your guidelines in place. If you're using tools like ChatGPT as an external vendor, keep in mind it will not be designed specifically for news use.
I also encourage newsrooms to consider building stuff that’s more solid in the longer term. We've seen a lot of uses of AI right now that have reached the prototype level. You can work on production and you can do these types of tasks, but if it remains in the prototype stage, then they tend to close down after a little while. If you're a smaller publisher, and you're using those tools, just make sure that you have a longer-term plan for how you're using them. Make sure that you're not just spending lots of time and effort trying something out only for it to die out afterwards.
The image at the top of the piece explores the visual culture of generative artificial intelligence landscapes, positioning it as a "new frontier" that echoes the 1850s to 1870s Manifest Destiny paintings (often associated with the Hudson River School). The base image, titled 'Westward the Course of Empire Takes Its Way' by Emanuel Gottlieb Leutze (1868), is one of many propagandistic paintings that worked to lure settlers westward while “conveniently” concealing the ethnic cleansing of Indigenous populations.
In every email we send you'll find original reporting, evidence-based insights, online seminars and readings curated from 100s of sources - all in 5 minutes.
In every email we send you'll find original reporting, evidence-based insights, online seminars and readings curated from 100s of sources - all in 5 minutes.