
In this piece
Introducing the News Atom: a metadata blueprint for journalism in the age of AI

A hand holding dandelions in the Cotswolds serves as a metaphor for how journalism's knowledge is becoming flattened in the digital age. Sannuta Raghu proposes the News Atom schema as a way to capture epistemic signals and maintaining provenance in a machine-readable format. Credit: Composite/Sannuta Raghu.
In this piece
Why this mattersWhen AI chatbots were first introduced to the world, we were all amused at how convincingly they produced marketing copy, and even poetry. But within months, they turned from writing tools into answer machines.
Journalism, which was scraped so that large language models or LLMs (which power AI chatbots) could learn grammatically correct language, is now being used as a factual substrate.
Facts are regurgitated but they are flattened: stripped of attribution, temporality and sensemaking signals, which journalists intentionally add to a news story.
This represents an inflection point not only for the news industry but for how society understands and trusts the information it consumes. The question now is: will journalism remain background data for AI systems, or could it shape the foreground as the sensemaking layer that anchors trust?
The News Atom is a metadata blueprint designed to respond to this question. It provides a way to codify journalism’s epistemic signals in a machine-readable format.
Here’s what it means – for journalists and for technologists.
A paradoxical product
Journalism has always been a paradoxical product. In his book, Who Owns the News? A history of copyright, Will Slauter explains that journalism is non-rivalrous: unlike food or fuel, one person’s consumption of news does not deplete it for others. It is also almost non-excludable: even if someone doesn’t pay for it, there is almost always a way to consume it. These are tell-tale signs of a public good. But journalism in 2025 isn’t a public good. Its economic model and survivability depends on controlling access and providing it to those who pay for it. Yet its civic function depends on wide distribution to inform life in a democracy.
As Styli Charalambous, co-founder and CEO of Daily Maverick said, “There is still value in the products that we create, in the journalism that we create - however, the market to sustain it has failed.”
This tug-of-war between existing market imperatives and its civic utility is what makes journalism’s epistemic signals so essential.
Two problems in the age of AI
The epistemic problem is where journalism becomes raw text – stripped of the type of knowledge, the strength of the evidence, and the source trail. A quote from a verified source, a fact cross-checked by a journalist, a sentence contextualising the analysis of an event is all reduced to word soup. The effort, time and resources journalists put into adding a sensemaking layer on to raw information is indistinguishable from grammatically correct internet chatter.
In addition, the design of today’s AI systems strips away provenance by default, making attribution very difficult. Digital systems have long commodified skilled editorial labour – leaving journalism to compete in a marketplace of content (and many times adapt to produce volumes of generic content to barely stay afloat). This is the economic problem.
What the News Atom does
The premise of designing the News Atom is this: Journalism is a value-added service in the knowledge economy. Every single day, journalists add new and verified knowledge to the internet. This knowledge underpins social, economic and political decision-making.
The News Atom is a structured, semantic unit that shows how this knowledge could be codified. It treats sentences not as raw text but as verifiable, interoperable, retrievable and reusable units. It is the smallest unit of storage and transport of a news story.
A sentence is the smallest self-contained unit of meaning in a news story. It usually contains an idea or concept that can be examined, retrieved, verified and recombined. Sentences are also marked by terminal punctuation marks, making them straightforward for both journalists and machines to identify. For this reason, the News Atom takes the sentence as the fundamental structural unit of epistemic value.
Could sentences in a news story carry specific meaning? The work of Teun A. van Dijk, who has provided foundational research on news discourse, and sociolinguist Allan Bell suggests this is possible.
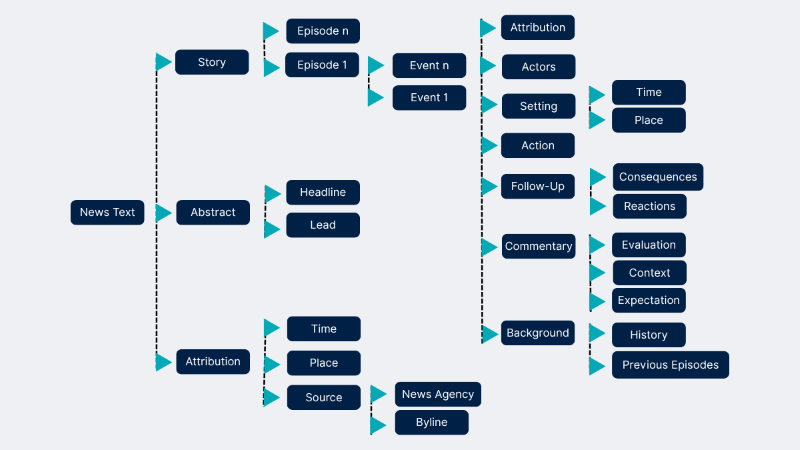
Allan Bell’s News Text structure is the basis of the knowledge_frame metadata field in the News Atom. It classifies a sentence into action, reaction, consequence, context, evaluation, expectation, previous episode, history and narrative.
Five of these are further classified into scalable downstream nodes:
(The full project PDF below explains all the design decisions and the rules for operationalising this).
In addition to the knowledge_frame, the News Atom also accounts for:
- Journalism produced not only in text but also audio and video.
- Modifications made to a developing story (ensuring a clean audit trail of reported facts).
- In-story attribution captured verbatim as in the news story ("According to the MET department…", "the finance minister said…", "Reuters reported") and direct quotes.
- The exact date of an event (not the publication date).
- Machine-readability of complex sentences (for example, "A 32-year-old man died and 95 others were injured during dahi handi celebrations in Mumbai on Saturday, The Hindu reported," from a published article on Scroll.)
- Reliably connecting each sentence to real world events and entities (like Wikidata and Geonames), increasing its interpretability in the information ecosystem.
- Grounding a sentence in standardised semantic frames and roles to structure reported events (using FrameNet).
- Relevant connection and interactivity in an archive.
- A human review process of LLM-based annotation as required.
- A distinction between “what happened?” (an observed fact reported by a journalist) and “why it matters and what it means” (sensemaking layer added by a journalist)
- Embedding of granular terms of use, licensing terms and syndication terms.
The structural gap
Journalism on the web is computationally flat. This is because a digital news story has no fragment-level metadata standard that preserves meaning - let alone provenance and rights information when ‘loose text’ moves beyond its original form. Existing frameworks operate primarily at the container level, and do not describe individual facts or sensemaking within it. (Check out another proposition, and an inspiration for this project that attempts to solve this problem.)
When such a news story is scraped for AI systems, semantics are stripped away - because they weren’t designed to be captured in the first place.
A senior technologist told me during an interview for this project that when LLMs were first being developed, the people training these models were “data scientists” and “machine learning engineers” – not “English majors”, “journalists”, or “natural language processing people”. They said: “I wasn’t there but I don’t think anyone stood up in a meeting and said, let’s throw out semantics. They understand data. [They probably said] how can we optimise this? How can we make it smaller, faster and more performant?” (Check out David Caswell’s peer reviewed work on structured journalism to understand this in detail)
This highlights a major structural gap for journalism-as-data in the age of AI.
Bridging the gap: the News Atom v1.0 schema
The News Atom is made up of the 15 metadata fields, which covers identity and governance, epistemic signals, provenance and relational context. Its canonical format is JSON (Javascript Object Notation).
This schema is version-controlled to allow for future evolution without breaking compatibility, and is designed for both live content pipelines and long-term archival. While JSON is the canonical format, it can also be serialised into formats like NDJSON for streaming, and Parquet for large-scale data analytics, without losing fidelity.

The full JSON schema is available in the project PDF below, or can be copied from newsatom.xyz.
atom_id, version, origin and language are standard metadata fields.
All the design decisions are available in the full project PDF at the bottom of this article.
What kind of news products could we build with the News Atom?
The News Atom is designed to work in a four-tiered organisational system. This is a proposed system, and one way to look at how an atom could interact with other atoms in a live pipeline or archive.

When a text article is picked up for annotation, the LLM first parses it to identify and extract the various events it reports about. For audio or video, it is first converted to time-stamped text. Each event is identified by an actor, action, object and location and labelled accordingly. After this, atoms are extracted and linked to an event. (An event will have multiple atoms). Each event can be linked to related events in a repository or event-bank. The event-bank can become a component of the larger archive.
This system enables event level clustering and topic level clustering. Further downstream, this also enables reported-facts clustering and journalistic-sensemaking clustering. Here a few examples of this could be used for:
Granular licensing and syndication APIs: With atom-level licensing information, a sensemaking cluster could be priced differently than a reported-facts cluster. A deeply reported topic or event can be priced differently than news updates.
User engagement with the archive: The News Atom’s granularity could allow for dynamic exploration of the archive at the user’s end. Think deep timelines and story arc visualisations, retrieved-context tooltips, vantage-point based rewrites and versions of an event, entity-specific pages or knowledge_type based clustering (“all reactions to Trump’s tariffs” in one place).
Smart archives: Instead of keywords, search could allow “observed_facts on climate change” within a specific date range or location, or “analysis citing the World Bank” or “all allegations against politician X” or “all speculation about Ether/ETH in 2025”. If the archive is vectorised, the News Atom is complementary: Vectors can be used for discovery, and News Atom could provide precision.
Why this matters
One of the biggest complaints from systems that process journalistic content today is that the data is not structured enough to be used reliably. The News Atom provides a way for the news industry to structure, define and embed its own meaning rather than having that meaning imposed by external systems.
When structured data like this is available, there is no longer an excuse to ignore or reject the rich cues it encodes. The challenge then shifts from availability to adoption, ensuring that these cues are actually valued and implemented in the wider information ecosystem.
Even three years ago, developing, testing and refining a schema like this would have been painstaking and limited by both tools and imagination. Today, large language models have made it radically easy to experiment and see what computationally rich journalism could look like in practice. And yet, there’s a deep irony here: the very tool that has unlocked new ways to express the value of journalism is the same that refuses to acknowledge it publicly.
The task ahead is to resolve this paradox, and to use these tools to ensure that the labour of journalism is visible, credited and compensated.
A demo of the News Atom v1.0, and what a news article looks like under the hood can be viewed at newsatom.xyz. In the future, updated versions and errata will be documented here too.
Disclaimer: This project is an attempt by a journalist to codify journalism’s epistemic layer, not a software engineer’s final specification. The News Atom will evolve through feedback and testing. If you see ways to improve it – technically or conceptually – please get in touch at news.metadata@gmail.com.
More on:


