

News
“Alarm bells are ringing in my brain” - Our Digital News Report India launch panel on low trust and shifts in news habits


The author at an AI workshop for Filipino newsrooms in September. Photo: US Embassy in the Philippines
The Philippines has one of the world’s most transparent budgeting systems. But ordinary citizens rarely get involved in the budgeting process. At a survey conducted in 2023 by the International Budget Partnership, the country scored an impressive 83 out of 100 in budget oversight and 75 out of 100 in transparency. But it only scored 33 in public participation, showing that citizens don’t participate in fiscal decisions.
When examining budget documents, it’s easy to see why. The Philippines’ Department of Budget and Management publishes both the proposed and the approved versions of the country’s budget every year. Each document contains a line item of every expense for the government for the year.
This means that the 2025 National Expenditure Plan is a beast of a document. It comes in a 56 MB Excel spreadsheet that contains more than 730,000 items. The 2024 General Appropriations Act, the approved budget for this year, comes in a 60 MB Excel spreadsheet, with nearly 700,000 items.
Given its sheer size, navigating through the data is a huge challenge. Just opening the files on a typical laptop computer and trying to filter the data often leads to frozen screens. Extracting any meaningful data means using a professional business intelligence tool or knowledge of a scripting language such as Python or R.
It’s also challenging to make sense of the document. It contains 18 columns, but they aren’t always used in the same manner. For example, for infrastructure projects under the country’s public works department, details of the project are included in a column called ‘DSC,’ which refers to a description of the project. For information related to public schools, however, the name of the school is located in another column unhelpfully named ‘UACS_OPER_DSC.’ This is because the budget units of every government agency separately fill out a form before the country’s budget and management department compiles all the disparate documents into one big dataset.
Unfortunately, there’s no guide available to map this information. If you’re a journalist, a researcher, or just a member of the public, you would need to know the nuances of how the budget document is encoded to find exactly what you’re looking for.
As a result, for all its openness, the budget document remains the domain of technical experts. Both the budget department and the legislators in charge of oversight hire experts to help them make sense of the document. But journalists, civil society groups, and regular citizens are a step or two removed from the process.
Veteran journalist Norman Bordadora, who has spent decades as a reporter and an editor covering the budget process, told me that from his experience many reporters rely on summaries given by the department or tips from congressional staff to find newsworthy items. While bigger news organisations have data departments, individual journalists and small newsrooms are unable to dive deep into the document in more meaningful ways.
This got me started on a project to see if I could use AI to create a tool that would allow anyone to interact with the Philippines’ budget more easily. Here’s how I did it.
To get started, I tried uploading this year’s budget file into a Custom GPT I created called the Budget Bot. I’ve used Custom GPTs extensively to create AI tools for the newsroom, and I even taught a workshop on using them at the CUNY School of Journalism. I would say that right now Custom GPTs are the best way to share both complex custom instructions and common datasets, uploaded as a set of Knowledge Files, for a large group of users.
ChatGPT handles data through a feature called Code Interpreter, in which it generates Python code to query datasets and then executes them in an internal Jupyter Notebook. Furthermore, these features are accessible to anyone with a subscription to a paid version of ChatGPT, which could be as low as $20 per month.
To get started, I put in initial instructions that gave it a description of the task as well as the budget spreadsheet as an Excel file.
## You're a bot designed to help users retrieve information about the Philippine budget from GAA-2024.xlsx.
It contains the following fields:
I only included descriptions for the columns that contained text data in the budget. The rest of the columns contained various ID numbers related to the Philippine government’s Unified Accounts Code Structure (UACS), a coding system that helps agencies with tracking funding sources, cash management, accounting, and audit.
Immediately, I ran into trouble. The Budget Bot generated Python code using the Pandas library But when loading the Excel spreadsheet, the execution of the script always timed out. It tried to fix the problem, but it timed out again.
A 60 MB Excel file was proving too much for the system. So I tried another approach. On my desktop, I converted the budget file into a CSV spreadsheet. It generated a bigger file, almost 200 MB, but I was able to upload it. This time, when testing the budget bot, the script did not time out. While it was still a bit slow, it worked perfectly. To optimise it further, I went back to the CSV file in my desktop and the UACS ID columns, reducing the size by about 25 MB.
Lesson No. 1: When working with Custom GPTs, I found CSV files were better for working with large datasets.
The Budget Bot works by taking the user’s question in plain English and turning it into Python code that it will execute to search the dataset.
For example, if a user types in, “Show me the budget for the Department of Health,” the bot would need to generate and execute Python code that would search the departments column for the term “Department of Health.”
During my initial testing, the biggest issue I encountered was getting the Budget Bot to search for the correct things inside the budget. For example, the bot was usually smart enough to figure out that a user who is searching for “UP budget” is searching for details about the University of the Philippines. But it wasn’t smart enough to know that the budget for the school was listed in the column for agencies under the name “University of the Philippines System.”
I wanted to give the bot a leg up. Interestingly, the best way to do that was to use the bot itself! Using the dataset, I asked it to generate a text file with a list of unique values found in the first two columns, which are entries for Department and Agency. I added this to the bot’s Knowledge Files, and added instructions for the bot to check the list first before generating the Python code, to make sure that it would know the exact search term to use.
Here’s my instruction: “If the user is searching for departments or agencies, determine the exact name of the department or agency first. Do not guess.”
The results were mixed. Sometimes, the bot would follow the instruction to check the file first. But it would often just ignore that instruction and search for what it thought was the correct search term. Anyone who has worked extensively with chatbots will recognise this pattern.
I tried a different approach. Instead of a text file, I asked it to generate the same list of departments and agencies, but this time in a JSON format. I then uploaded this JSON file into the Budget Bot’s Knowledge Files with the instruction to check the list first. This approach worked.
It turns out that Custom GPTs would “read” text in JSON format first before generating the Python code and running Code Interpreter. This meant that it already knew the correct names of each department and agency before it generated the Python code to query the dataset. Since implementing this change, I haven’t seen any issue with the Budget Bot searching for the wrong Department or Agency.
It also made the Budget Bot smarter about searches. If a user asked for budget items related to sports, it would immediately figure out that the user wanted information from agencies such as the Philippine Sports Commission or the National Academy of Sports. Asking the bot for budget items related to early education would return results from Early Childhood Care and Development Council, an agency under the Department of Education.
I tried to push my luck to see if JSON files would work as an index for other columns. These columns usually had more unique information, and the files ran much larger than the file containing just Departments and Agencies.
In testing, I found that instead of checking them, the budget bot would ignore JSON files altogether if they were too big, rendering them useless. In the end, I simply went with the original JSON index containing Departments and Agencies.
Lesson No. 2: Use JSON files to create indexes when working with large datasets, but make sure they are not too big.
I also tried other optimisations, like breaking down the dataset into multiple files, and putting back the UACS IDs that the Budget Bot could then use to combine the data back together through JOIN commands. This resulted in the bot having to generate more complex Python code, which resulted in frequent errors and garbage data being retrieved. I went back to the original flat dataset.
Lesson No. 3: It’s better to provide the data as a flat table instead of splitting it across multiple files for Custom GPTs.
The rest of the work I did involved testing different searches. A lot of it was about making sure that the bot was searching for the right terms in the right column. In this case, the best tool I used to improve the Budget Bot was the Budget Bot itself.
For example, through trial and error, I found that details about infrastructure projects are in the column DSC. To make the Budget Bot better, I simply needed to add a line in its instruction set: “DSC - If the question is about construction of infrastructure projects related to public works, the name of the project is likely to appear here and should be part of the search.”
At workshops and meetings the past few months, I did hands-on demonstrations of the Budget Bot and collected their feedback. Guided by their comments, I used the Budget Bot to find further nuances within the budget document itself.
I discovered, for example, that the names of state universities and colleges could be found in the column UACS_AGY_DSC, while names of primary and secondary schools would be found in the UACS_OPER_DSC column. This “operational description” column would also be where you could find the location of regional and district offices of various departments, the names of public hospitals, the names of prisons and penal farms, and the locations of embassies and consulates. All these were added to the main instruction set to allow the Budget Bot to find things easier for future use.
By exploring the budget document through the Budget Bot, I also found more esoteric details, like how line items for embassies and consulates are marked in the DSC column with arcane terms. Again, these peculiarities were added to the main instruction set.
This part of the process was very similar to my usual work as a reporter, exploring large amounts of data to find noteworthy things and to document them. Instead of publishing my findings, though, I used them to inform an AI tool so other journalists and researchers would not have to go through the same tedious steps. When building an AI tool like this, there is so much value that journalists could bring to the design process.
Lesson No. 4: Having journalistic skill and expertise is a key asset when teaching an AI tool how to search for information like a journalist.
When I asked for feedback about the tool, Journalism Professor Karol Ilagan pointed to the most obvious thing still missing from the Budget Bot: being able to compare the latest budget with previous years. Ilagan is a longtime investigative journalist, and many of the most interesting fiscal stories she had worked on in the past involved analysing movements from one year to another.
I wondered if the system could handle more than one budget file. After my initial testing with the country’s approved budget for 2024, I tried to add the 2025 proposed budget to the Knowledge Files of the bot. With just one line added to the instruction set describing the new file, the bot worked perfectly with the new dataset. To make this dataset smaller, I then also removed the UACS ID columns.
I tried to push the limit of the system by adding budget files all the way back to 2020, removing the UACS ID columns each time. The bot still worked except for an issue: some of the agencies have changed names through the years.
It was easily fixed. I just asked the Budget Bot to generate additional entries for its own JSON key for departments and agencies that existed in the older budget files.
Having all the budget files in a single bot, however, resulted in a severe degradation of performance. Simple queries would take several minutes, and would more often than not time out. So I decided to just keep three datasets in the bot: the budgets approved for 2023 and 2024, and the 2025 proposed budget.
I still wanted the main bot to have comparisons beyond just the three years. To do this, I simply used the bots to create an “aggregates” dataset, containing totals by Department and Agency from 2020 all the way to 2025. I then added a bunch of instructions to the bot to look at the aggregates dataset first before loading the bigger line item budget files.
For aggregate data queries:
With these instructions, users can compare figures from 2020 to 2025 in the same bot, even though the line item details are only available from 2023 to 2025.
To explore budget data from the earlier years, it took about 20 minutes to create another Custom GPT with minor tweaks to the original instruction set.
Lesson No. 5: Custom GPTs can handle multiple large datasets, but performance could degrade if there are too many.
When refining the bot, I focused on accuracy and usability improvements. This meant making sure the bot dropped null values when doing totals; adding commas to improve readability of large figures; showing all columns for complete information instead of just one or two where the search terms were found; and displaying the correct values because the original budget data was encoded with figures in thousand pesos.
I also made sure the bot only looked up the budget for the upcoming year when the user did not specify a year, instead of loading every dataset available.
Here's a question I would usually get at workshops showcasing the bot: how do we know it gave us the correct information? ChatGPT users are able to see the Python code generated to retrieve the data from the different datasets. To improve transparency further, I added instructions for the Budget Bot to explain explicitly what information it was looking for in which datasets. See the screenshot below.
I have since published the full instruction sets and the datasets on GitHub so that anyone interested can inspect these themselves. They could also be used to build the tool on other chatbot platforms. I also created a user guide for those interested in trying out the Budget Bot.
The Budget Bot is already quite useful as a tool for information retrieval. It’s a great tool for finding both aggregate data (“What is the total budget for the Department of Education?”) and granular data (“Show me all the confidential budget items for 2024”).
It has been even more helpful to people who already have some level of familiarity with the budget document and with government processes. For example, someone looking for specifics like “Show me all the intelligence fund items under the police” would find more meaningful data than “Find all expenditures related to infrastructure.”
It’s amazing how well it works, considering it was a one-man effort that was built using a $20-a-month ChatGPT subscription. The biggest bottleneck was finding journalists, researchers and academics to test it. It requires a ChatGPT subscription, and not many people have it yet. Most of the feedback I got came from my presentations.

The Budget Bot is not just a toy. Budget deliberations have been underway in the Philippines’ legislature for the past two months. When the new budget is approved by the end of the year, the Budget Bot would be the easiest way to check the differences between the budget proposed and the budget approved by Congress.
Adding a new budget data file and updating the instruction set takes just a few minutes, while new budget datasets are only published a couple of times a year, so it is easy enough to maintain.
Once you do that, it can be an evergreen tool for Filipino journalists. When the next typhoon comes, they can use the Budget Bot to find what flood control projects have been funded by the government over the years. When schools open, they can check how much money the government allocated for each school district. Academics, researchers, technocrats and civil society representatives can benefit from the tool as well.
As with many other generative AI tools, being able to trust the results is the biggest hurdle. Over the next few months, I hope to work with newsrooms, civil society organisations, and academic departments to show them how to get the most of the tool. I hope it becomes a showcase for how AI can democratise access to data.
To serve as a showcase of visualisations using data from the Budget Bot, I also plan to create a graph gallery where users can give their own submissions.
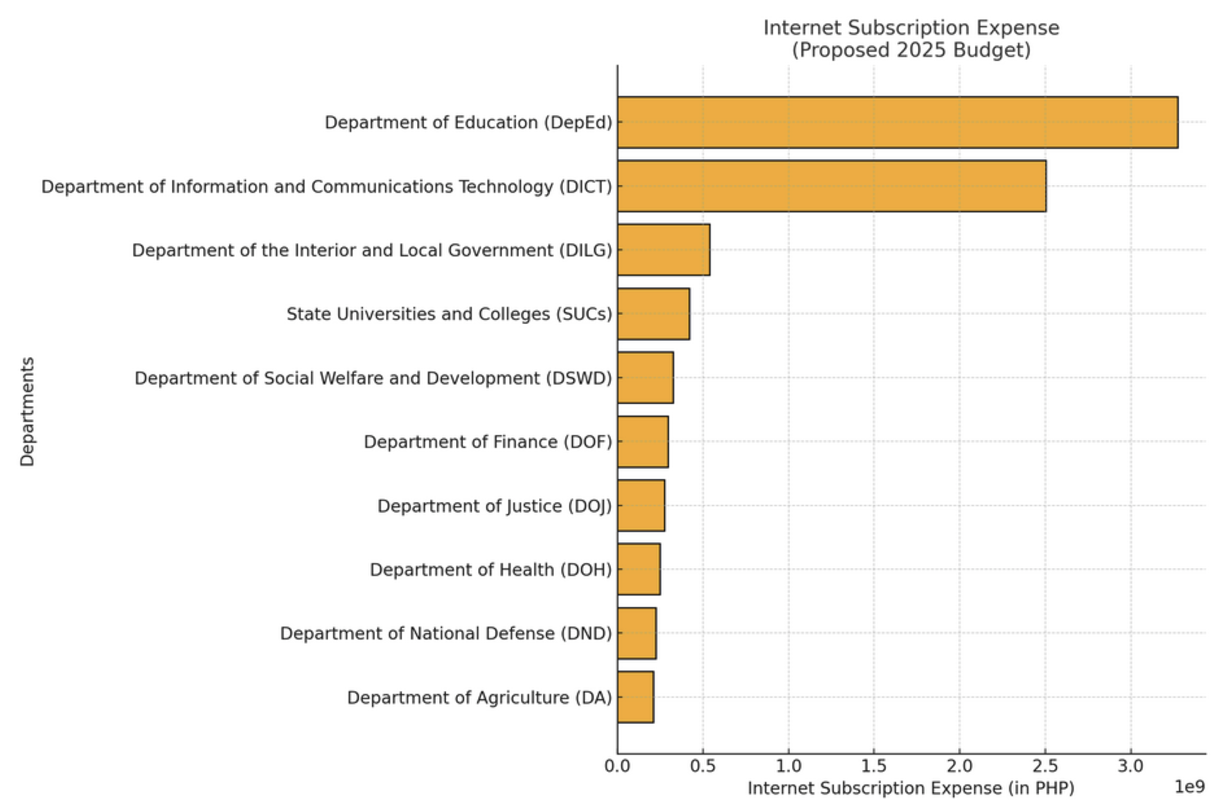
I hope the Budget Bot inspires other newsrooms around the world, especially those from developing countries, to explore how AI tools can help them access larger datasets even without the manpower or technical resources of larger media organisations.
This article was also published by Generative AI in the Newsroom and can be found in this link.
In every email we send you'll find original reporting, evidence-based insights, online seminars and readings curated from 100s of sources - all in 5 minutes.
In every email we send you'll find original reporting, evidence-based insights, online seminars and readings curated from 100s of sources - all in 5 minutes.


