
Podcasts
Our podcast: Digital News Report 2026. Episode 4: How people are using AI chatbots for news


People take part in the Russian March, organised by nationalists and activists of far-right political groups, to mark the National Unity Day in Moscow, Russia November 4, 2018. REUTERS/Sergei Karpukhin
Any journalist who’s done online investigations knows there’s simply too much evidence for one human to ever collect or investigate. Too often, we are overwhelmed with a flood of information: tens of thousands of social media posts, images and other media.
Our team from BBC Eye, which works on original documentary investigations from around the world, wanted to see if AI could help solve this problem. We opted for AI agents – a collection of large language models (LLMs) that can coordinate and execute multi-step tasks under human supervision. When connected to external environments such as the Internet or databases, these agents can fetch and analyse relevant social media content at scale, performing work that our team might otherwise not have the time to undertake.
We used this approach as part of a recent published investigation on Russia’s rising nationalist vigilante movement, building a multi-agent AI system we named Haystack to help us explore new emerging forces in daily Russian life. The team included BBC Eye’s open-source investigators, who are specialists in gathering and analysing public information, and Russia-focused reporters, along with help from computational journalists at Stanford University.

This is how we developed and used this system.
While we did extensive on-the-ground reporting in Russia for the investigation, the country’s restrictive journalism environment made this kind of analysis additionally beneficial in supporting and deepening our research.
The project began when we noticed that social movements were disrupting Russia’s domestic politics while the Kremlin was waging its full-scale invasion of Ukraine. New groups emerged promoting far-right and nationalist beliefs, and these views were disseminated across Russian social media.
Using source reporting and data journalism methods, the BBC Eye global investigations team had already revealed how Russkaya Obshina, currently the largest nationalist group, was operating a nationwide campaign against migrants and those opposed to “traditional values”, in concert with the Russian authorities. The team also saw financial documents that suggested the group had been funded by charitable foundations run by figures close to the Kremlin (a finding Russkaya Obshina rejected).
The reporting included over a dozen interviews with former and current members of the group, migrants, Russian citizens that have been targeted, and experts monitoring the situation. But to understand the scale of this movement, the team created and leveraged a new AI system to harvest, analyse and surface leads at a scale we could never have handled using traditional methods.
We were aiming to use AI to mirror multiple tasks of an investigations team in a single application: a computational journalist interacting with a webpage or API to download data, a reporter assessing social media posts for leads, and a data specialist producing numerical findings.
It was our first foray into multi-agent work and required lots of experimentation and iteration: both in building an agent-driven workflow that made sense for reporters, and ensuring that the agents at each step were performing their tasks effectively.
We used Haystack to gather 10,000 social media posts from over ten Russian nationalist groups and produced 55,000 assessments of their content for signals such as nationalist ideology, references to migrants, anti-migrant raids, and expressions of violence against minority groups.
With Haystack’s assistance, the team found that Russkaya Obshina appeared to have the most prolific on-the-ground presence when compared with other nationalist groups, organising patrols across Russian towns and cities, and raids on workplaces, shops, nightclubs, and hostels.
Haystack stitches together multiple AI agents that perform a variety of tasks. Those include:
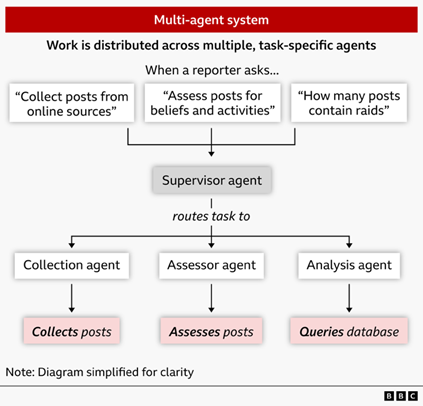
The team built the application using LangGraph, a programming library that enables developers to build AI workflows by connecting multiple agents that can perform these different tasks in one standalone structure. LangGraph allows developers to integrate any of the popular open-source or cloud-hosted LLMs, such as OpenAI’s GPT and Google’s Gemma models.
From a reporter's perspective, the system resembles one of those choose-your-own-adventure books. The journalist can interact with Haystack and travel down one of several well-defined paths.
An initial challenge was ensuring the supervisor agent, which delegates tasks down chosen research paths, followed the direction provided by the journalist. We solved this issue by giving the supervisor agent examples of accurate behaviour and having the system ask clarifying questions to resolve unclear reporter input.
At each stage of the process, the reporter is asked to provide instructions and clarifications to agents.
We had explored building a more automated system, where agents would independently take multi-step decisions, like collect, assess, and analyse data all based on a single complex prompt. But we found that having the reporter provide input at each stage of the process, determining which and how many posts an agent should assess, reduced the chance of LLMs lapsing into guesswork and taking the research down unintended routes. We also thought it was important to have a journalist in the loop, so that oversight was maintained over agent decision-making.
Once we’d designed the system, the team put it to work by creating a seed list of nationalist and far right groups that we were interested in investigating. Drawing on this list of over ten nationalist groups, we used the collection agent to gather posts. This process created a unique dataset that the system could then assess for journalistic leads – helping us understand the nature of the nationalist movements that appeared to be growing in Russia.
Our next step was to ensure the agent’s assessment of online content worked reliably, so we continually checked Haystack’s output and made adjustments to prompts to improve the results.
As we spent time using the system, we discovered that responses got more helpful to our reporting as we removed ambiguity from the inputs’ wording. For example, in the beginning journalists would ask the system, “Does this post contain raids? Please label it ‘definitely’, ‘definitely not’,’ probably’, ‘probably not’…”. But we found that by narrowing the LLM’s options to “yes”, “no”, “not sure”, we surfaced more precise leads.
In the background, this process was building a large database where we would review the assessments and examine the reasoning the LLM applied to its decisions.
The system also allowed reporters with little or no technical training to analyse data, for example, counting the number of posts describing anti-migrant raids. Traditionally, this type of data analysis requires fluency in programming and database querying language. Now a reporter without data training can ask questions in natural language, which Haystack translates into database queries before returning a straight-forward summary of the query’s results.
Once we were confident in the system we set Haystack loose to gather and assess more social media posts, surfacing hundreds of leads that we might have overlooked, which were also verified by members of our team who manually reviewed the evidence.
The system allowed us to start quantifying the degree to which nationalist groups were inciting violence against migrants, conducting on-the-ground raids, and mobilising alongside Russian authorities in street-level actions.
This is work that would have required weeks or months of painstaking effort, sifting through thousands of social media posts manually. Haystack allowed us to cut through the noise and get at what we were really interested in: the extent to which these Russian groups talked about their real-world activities.
The system also surprised us with some unexpected benefits along the way, surfacing euphemisms and derogatory language used to describe migrant workers such as “visiting specialist” or “workaholics”.
The multi-language capabilities of the LLMs underlying Haystack allowed non-Russian speakers to uncover such language and verify the accuracy of terms with Russian experts on our team. The ability to work across languages holds huge potential for our newsroom and others that focus on cross-border investigations.
Haystack allowed us to explore the scale and nature of the nationalist movement in Russia, in particular revealing nuances about the activities of Russkaya Obshina. With Haystack, our reporters could more clearly understand the emerging trends by harvesting and analysing a much larger volume of posts. The tool expanded our ability to scale the team’s capacity and, in the process, helped guide our reporting and clarify the story.
We designed Haystack in a way that could work with any type of investigation. As we think about future directions for the project, we’re considering expanding the number of data sources beyond Russian social media that Haystack can harvest data from and analyse. For example, other online data sources and public records and documents.
We are also thinking about how such a system aligns with existing patterns of work in the newsroom. Reporters who are experts on particular beats and geographic regions might typically search for examples of social media content that help tell a story.
Our system can harvest such information under their direction. Reporters can then spend some time reviewing and categorizing a small subset of such content, and then enlist Haystack to gather and analyse a much larger volume of posts. We believe such AI-powered systems hold potential to expand our reach, allowing us to work on stories that may otherwise never be told.
The emergence of generative AI has allowed malicious actors to pollute information environments faster than ever. The only way to counter the flood may be to find trustworthy ways to harness AI ourselves.
Additional contributors to this project were Andreea Jitaru, Ned Davies, and the BBC Research & Development team.
In every email we send you'll find original reporting, evidence-based insights, online seminars and readings curated from 100s of sources - all in 5 minutes.